

 Benjamin Carter
Benjamin Carter
在数字化转型的浪潮下,数据已经成为企业最宝贵的资产。无论是电商选品、市场调研、广告投放还是AI模型训练,都离不开对海量公开数据的高效收集。网页抓取(Web Scraping)正是在这种需求背景下,被广泛应用的一种自动化技术。本文将从多个角度带你全面了解网页抓取的核心知识,并结合实践案例,推荐可靠的住宅代理服务商 Cliproxy,助力企业实现更高效的数据获取。
网页抓取(Web Scraping)是指通过程序自动化访问网页,并提取网页中有价值信息的过程。它能帮助企业和个人在短时间内收集大量公开数据,而不必依赖人工逐一复制粘贴。
举个例子,如果一个跨境电商卖家想要对比不同平台的商品价格,就可以使用网页抓取工具自动获取产品信息,并将数据存储到数据库或Excel表格中,方便后续分析。
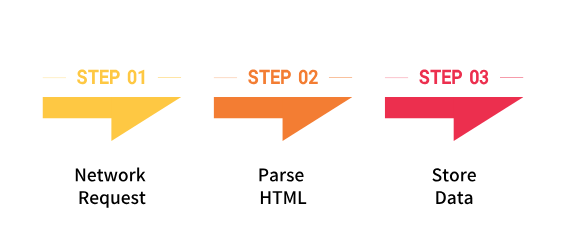
网页抓取通常依赖 网络爬虫(Web Crawler) 来实现。其基本工作流程可以分为以下几步:
例如,Python 的 requests 和 BeautifulSoup 库就可以快速完成一个简单的爬虫原型。
虽然名字相似,但网页抓取(Web Scraping)和屏幕抓取(Screen Scraping)并不是一回事。
换句话说,网页抓取是“在网页底层代码中取数据”,而屏幕抓取是“从显示器上抄数据”。
按工作方式分类有以下几种类型。
不同类型的爬虫适合不同任务,企业在选择时需要结合自身业务需求。
网页抓取技术已经深入到多个行业的日常运营中,主要应用包括:
在全球化运营中,网页抓取的作用日益凸显。
要想高效、合规地进行网页抓取,建议遵循以下最佳实践:
其中,代理IP的使用至关重要。高质量代理不仅能提升抓取成功率,还能保持数据的完整性和稳定性。
在网页抓取中,代理服务的选择决定了效率和质量。如果代理IP不稳定或重复度高,可能导致请求失败率增加,甚至影响项目进度。
相比数据中心代理,住宅代理(Residential Proxy) 更适合网页抓取场景,因为它们来源于真实的家庭网络,具备更高的稳定性与纯净度。
这里推荐 Cliproxy,作为专业的住宅代理服务商,具有以下优势:
无论是电商卖家、市场研究公司,还是AI训练团队,Cliproxy都能为其网页抓取提供强大支持。
网页抓取是企业在数据驱动时代的重要工具,能够帮助快速获取结构化信息,为决策提供依据。理解其原理、类型和用途,并结合最佳实践方法,可以极大提升数据采集效率。
尤其是在代理服务选择上,推荐使用像 Cliproxy 这样高质量的住宅代理服务商,帮助企业构建稳定、安全、高效的数据抓取流程。
在数字化竞争中,谁能更快、更准地获取和利用数据,谁就能在市场中抢占先机。
Q1:网页抓取被应用于哪些领域?
A:网页抓取在多个行业都有应用,包括电商价格监控、市场调研、广告投放优化、品牌舆情分析、学术研究,以及AI模型训练等。
Q2:网络抓取是否合法?
A:网络抓取是一种技术手段,本身并无对错。关键在于使用方式和数据来源。一般来说,采集公开数据并遵循相关网站的使用规范是可行的,但在应用过程中应注意合规和合理使用。
Q3:网页抓取有什么实例?
A:常见的实例有:
Q4:ChatGPT能否进行网页信息抓取?
A:ChatGPT本身不直接执行网页抓取功能。但它可以结合搜索工具获取公开信息,或者为开发者提供爬虫实现思路。若需要大规模数据采集,通常需要借助专业的抓取工具或代理服务。


