

 Benjamin Carter
Benjamin Carter
In the wave of digital transformation, data has become the most valuable asset for businesses. Whether it’s product sourcing in e-commerce, market research, advertising, or AI model training, all rely on the efficient collection of massive amounts of publicly available data. Web scraping has emerged as a widely used automation technique under this demand. This article provides a comprehensive overview of the core knowledge of web scraping, combined with practical use cases, and recommends a reliable residential proxy provider — Cliproxy — to help businesses achieve more efficient data acquisition.
Web scraping refers to the process of automatically accessing webpages through programs and extracting valuable information. It enables companies and individuals to collect large amounts of public data in a short time, without manually copying and pasting.
Example: If a cross-border e-commerce seller wants to compare product prices across platforms, they can use a web scraping tool to automatically collect product information and store the data in a database or Excel file for further analysis.
Web scraping typically relies on web crawlers to achieve its functionality. The basic workflow includes:
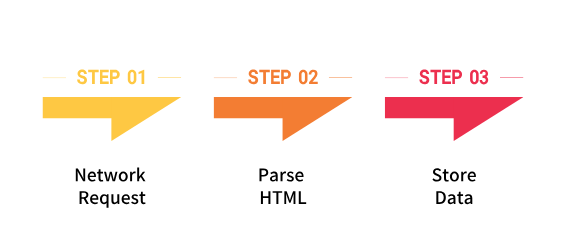
For instance, Python’s requests and BeautifulSoup libraries can quickly build a simple crawler prototype.
Although the names sound similar, web scraping and screen scraping are not the same.
In short:
By working methods, web crawlers can be categorized into:
Different types of crawlers are suitable for different tasks, and businesses should choose based on their needs.
Web scraping has become deeply integrated into daily operations across industries. Common applications include:
In the era of globalization, the role of web scraping is increasingly significant.
To conduct web scraping efficiently and responsibly, follow these best practices:
Among these, proxy IP usage is critical. High-quality proxies improve success rates and maintain data integrity and stability.
In web scraping, the choice of proxy service directly affects efficiency and quality. Unstable or overused proxy IPs may cause request failures and slow down projects.
Compared with data center proxies, residential proxies are more suitable for scraping since they come from real household networks, ensuring higher stability and authenticity.
We recommend Cliproxy, a professional residential proxy provider, with the following advantages:
Whether for e-commerce sellers, market research firms, or AI training teams, Cliproxy provides strong support for web scraping.
Web scraping is a vital tool in today’s data-driven era, enabling businesses to quickly acquire structured information for decision-making. By understanding its principles, types, and use cases — and applying best practices — organizations can significantly improve their data collection efficiency.
Most importantly, choosing the right proxy service, such as Cliproxy, ensures stable, secure, and efficient scraping workflows. In the digital competition, the ability to acquire and leverage data faster and more accurately determines who gains the edge in the marketplace.
Q1: In which fields is web scraping applied?
A: Web scraping is widely used across industries, including e-commerce price monitoring, market research, advertising optimization, brand sentiment analysis, academic studies, and AI model training.
Q2: Is web scraping legal?
A: Web scraping is a technical method and is neither inherently right nor wrong. The key lies in how it is used and the source of the data. Generally, collecting publicly available information while following relevant website usage policies is acceptable, but compliance and proper use should always be considered.
Q3: What are some examples of web scraping?
A: Common examples include:
Q4: Can ChatGPT perform web scraping?
A: ChatGPT itself does not directly perform web scraping. However, it can work with search tools to access publicly available information or provide developers with guidance on building crawlers. For large-scale data collection, specialized scraping tools or proxy services are typically required.
Start your Cliproxy trial

Benjamin Carter 2026-01-21 16:00 · 19 min read

Benjamin Carter 2025-09-18 16:00 · 12 min read

Benjamin Carter 2025-06-25 13:52 · 35 min read